 渠道合作
渠道合作大厂“补贴”,和鲸“种树”:AI应用生态战的另一种打法
2026年6月,一场围绕AI开发者的生态战争,正在全球范围内愈演愈烈。
华为开发者大会2026定档6月12日,聚焦HarmonyOS全新版本和AI核心能力;阿里魔搭社区发布首份AI开源人才报告,推出AI开源人才全息画像,同时正式推出Skills中心并全面开放核心OpenAPI;据最新报道,魔搭社区已服务2500万开发者,ModelScope的模型下载量突破1亿次。小米在4月底宣布启动百万亿Token创造者激励计划,30天内免费发放100万亿Token权益,还推出Agent生态共建计划;微信推出AI小程序成长计划提供云开发资源、AI算力等支持;B.AI甚至联合BNB Chain推出“百亿AI Token补贴”活动。
这些现象指向一个共同信号:开发者正在成为AI时代最稀缺、最宝贵的战略资源。谁能汇聚最多的开发者,谁就能在下一阶段的AI应用生态中占据主导地位。
而在这场开发者争夺战中,大厂采用的策略出奇一致——“补贴”,用Token补贴“买”开发者。但这个策略面临一个根本性挑战:补贴吸引来的开发者,会因为补贴退坡而流失。
和鲸的选择截然不同:它选择“种树”——用八年时间培育一片开发者生态的热带雨林,让开发者在这里既能生存,更能繁荣。
AI应用生态的结构性机会
为什么“中间层”比“底层”更值钱
Agent的规模化落地需要三层能力:底层的基础模型(“大脑”)、中间层的开发平台(“工具箱”)、应用层的落地场景(“用武之地”)。大厂集中火力投入底层模型研发,应用层的繁荣却需要海量开发者来驱动。
当前开发者生态面临一个深刻的“断层”危机:90%的原型项目止步于POC阶段,因为业务专家缺乏AI工程化能力,而技术团队不懂行业Know-How。AI编程工具让“写代码”变得简单,但Gartner预测40%的企业应用将集成AI智能体,业务需求爆发式增长,传统工程化流程却远远跟不上。
这个“断层”正是中间层平台的结构性机会。开发者缺的不是基础模型的调用能力,而是从想法到落地所需的全套工具箱——数据清洗、模型微调、算力调度、应用部署、API管理……缺一不可。
和鲸ModelWhale的能力体系,恰好填满了这个“工具箱”的每一个格子。正如前几周文章所述的RAG知识库、大小模型协同调度、可视化AI工作流编排,这些能力构成了开发者的“一站式生产力操作系统”——低门槛、高效率、可协作。
和鲸的“热带雨林”
三层生态如何形成“滚雪球效应”
和鲸的生态结构呈现出“热带雨林”式的分层特征——阳光雨露作用于顶层(开发者生态),养分流转于中层(合作伙伴生态),根系深扎于底层(内容与数据资产生态)。三层相互滋养,自我循环,形成“滚雪球效应”。
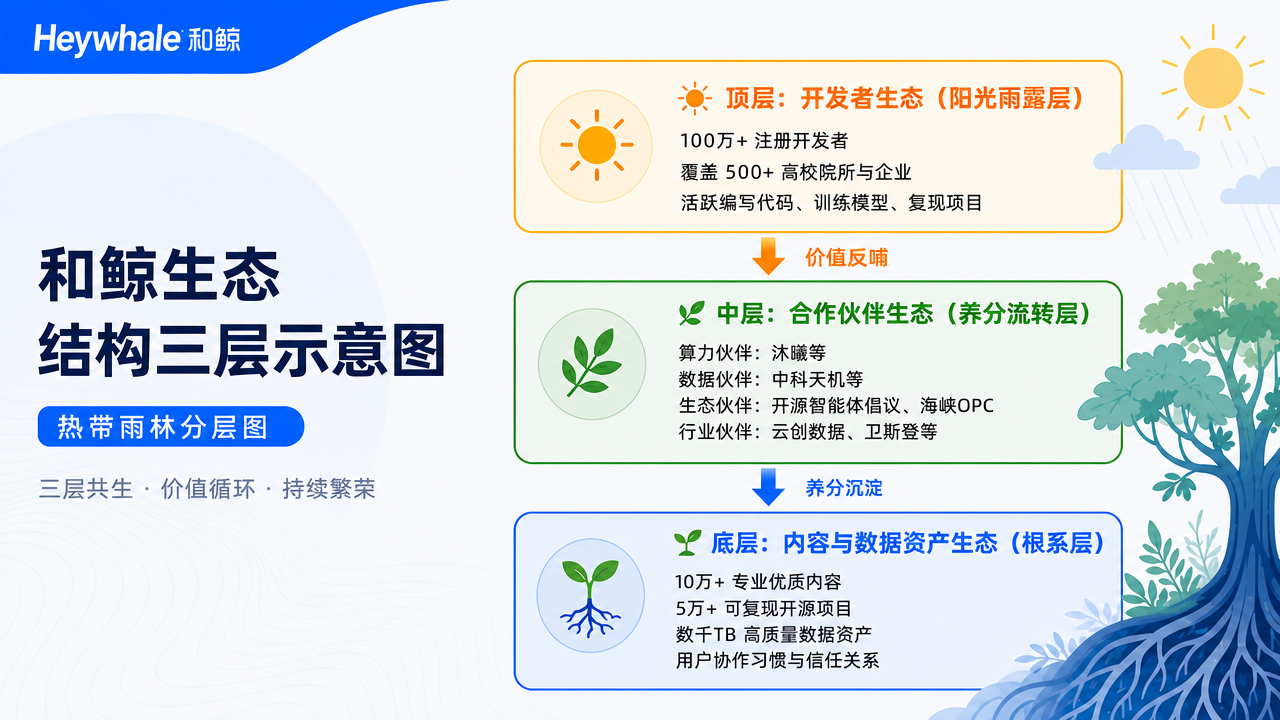
第一层——开发者生态:
100万用户的规模效应
和鲸社区已沉淀百万注册用户,覆盖超1000+所高校院所和企业机构。这些用户不是被动“刷帖”的流量用户,而是活跃的数据科学实践者——他们写代码、跑模型、做项目、写教程,是真正的“AI应用开发者”。
规模效应的核心在于形成“好平台→吸引开发者→产出优质内容→吸引更多开发者→更多产出”的正向循环。和鲸的“鲸选计划”正是这一循环的加速器:创作者发布原创项目可获得收益激励,优质内容涌现,激励持续加码。“365天深度学习训练营”每周评选最佳作品给予鲸币奖励,形成高频激励机制。用户在平台上既能学习先进经验、复用成熟代码,又能获得认可和收益,留存的理由远比“赚补贴”更充分。
第二层——合作伙伴生态:
从“单打独斗”到“多兵种协同”
开发者数量是生态规模的第一指标,但要真正繁荣,还需要形成“多兵种协同”的合作网络。和鲸在过去一年快速构建了覆盖算力、数据、工具、行业的合作伙伴矩阵:
算力伙伴:沐曦完成曦云C500、C550、C思N260与ModelWhale的兼容性测试,筑牢自主可控算力底座。
数据伙伴:中科天机与和鲸社区合作,“高精度数据-科研平台-开发者生态”链路正式打通。
工具伙伴:智能数据提取工具MinerU接入ModelWhale,文档智能化处理的效率和准确性显著提升。
行业伙伴:云创数据、鸿蒙生态等合作伙伴深化协同,共同赋能区域AI产业升级。
第三层——内容与数据资产:
时间沉淀的“生态壁垒”
10万+专业优质内容、5万+可复现开源项目,构成了和鲸生态“无法快速复制”的最硬核壁垒。这些内容不是“灌水”的低质帖子,而是经过社区筛选、验证的高价值资产。任何一个新开发者加入和鲸,面对的是一整套“开源项目库+教程库+数据集库+问答库”的知识体系。用户不再需要从零开始,而是可以站在数万项目的肩膀上直接做应用开发。
“热带雨林”的深层逻辑在于——它不是“自上而下”设计出来的,而是“自下而上”生长出来的。大厂可以用补贴“买”开发者,但无法在短时间内“种”出一个拥有数百万个相互连接的节点、数千TB高质量数据资产、以及经年累月沉淀下来的用户协作习惯的有机生态。
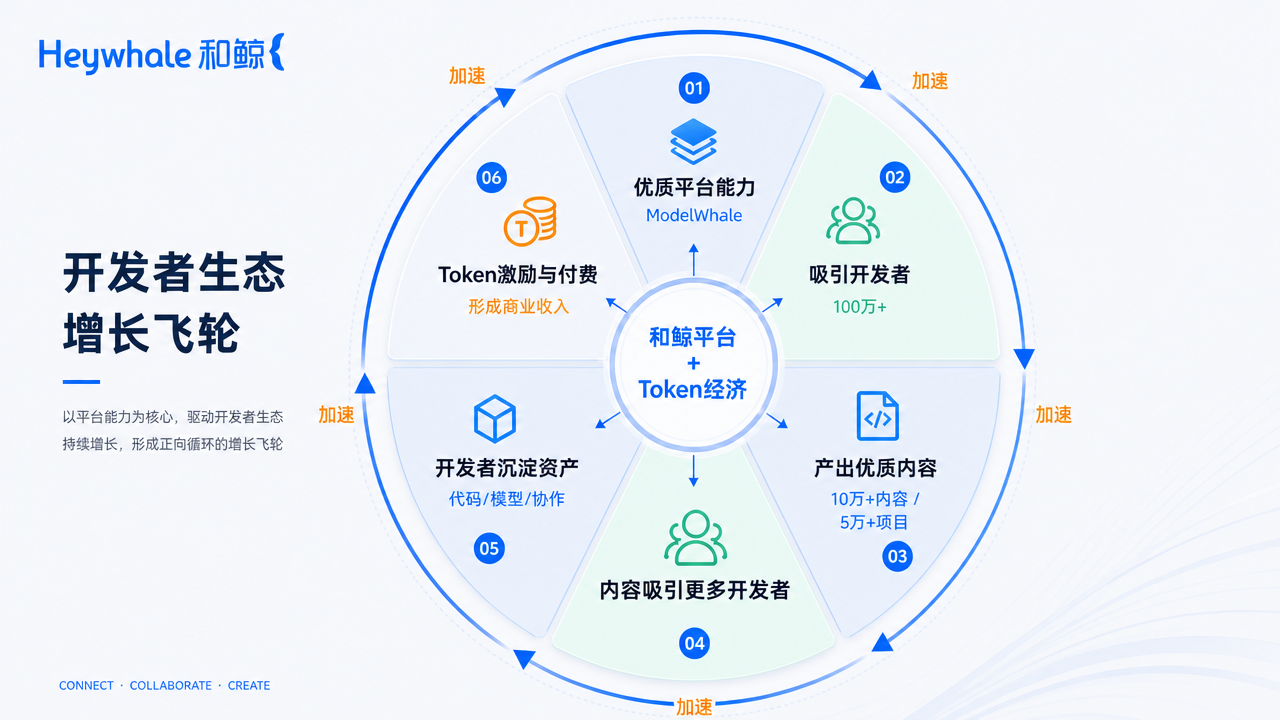
Token经济
让生态“自我造血”的价值引擎
传统的开发者平台面临一个普遍困境:用户规模越大,运营成本越高,但收入增长跟不上成本增长。因为平台需要持续投入算力成本、存储成本、运维成本来服务用户,而用户付费意愿有限。
和鲸的Token经济,正是打破这一困境的关键设计。
从运营视角看,Token经济解决了“用户越多成本越高”的难题——新用户通过免费Token体验平台算力;用户用完免费额度后自然形成付费意愿;高频用户在平台沉淀数据、代码、模型后,迁移成本大幅提升,因长期使用产生的协作习惯和高昂的数据资产积累,构成了极强的用户粘性。Token本质上是将“价值创造”与“价值分享”匹配起来——用户使用Token消耗算力,平台获得收入;平台将部分收入转化为社区激励(鲸币),激励开发者创造更多优质内容;优质内容吸引更多用户,形成生态飞轮的自驱动。
Token经济的底层逻辑是重新定义平台与开发者之间的价值关系——从传统的“平台提供服务、开发者付费使用”,转向“开发者创造价值、平台帮助开发者实现价值、双方共享增值收益”。在合作中客户并非简单地将ModelWhale视为采购工具,而是“共同构建贯穿数据、模型、应用与协同的智能平台”-——这种协同模式本身就是Token经济价值主张的真实写照。
与“补贴”模式对比
和鲸生态的底层优势
理解大厂和和鲸的差异,需要回到一个重要概念:网络效应——平台的价值与用户(或节点)数量的平方成正比。
用Token补贴“买”开发者的模式,本质上是线性增长逻辑:每投入一定的补贴成本,获得一定数量的开发者。补贴退坡,用户流失。这是一种“租赁式增长”——你租的是用户的时间,不是用户的忠诚。
而以和鲸为代表的“热带雨林”模式,是指数增长逻辑:每个新加入的开发者,都让平台对老用户的价值更高。当一个开发者上传一个新的开源项目,这个项目可以被其他用户复用、改进、再分享。平台的生态价值随着用户数量的增长而加速增长,而不是线性增长。这是一种“资产式增长”——你积累的是用户创造的资产,越积累越厚,越积累越不可替代。
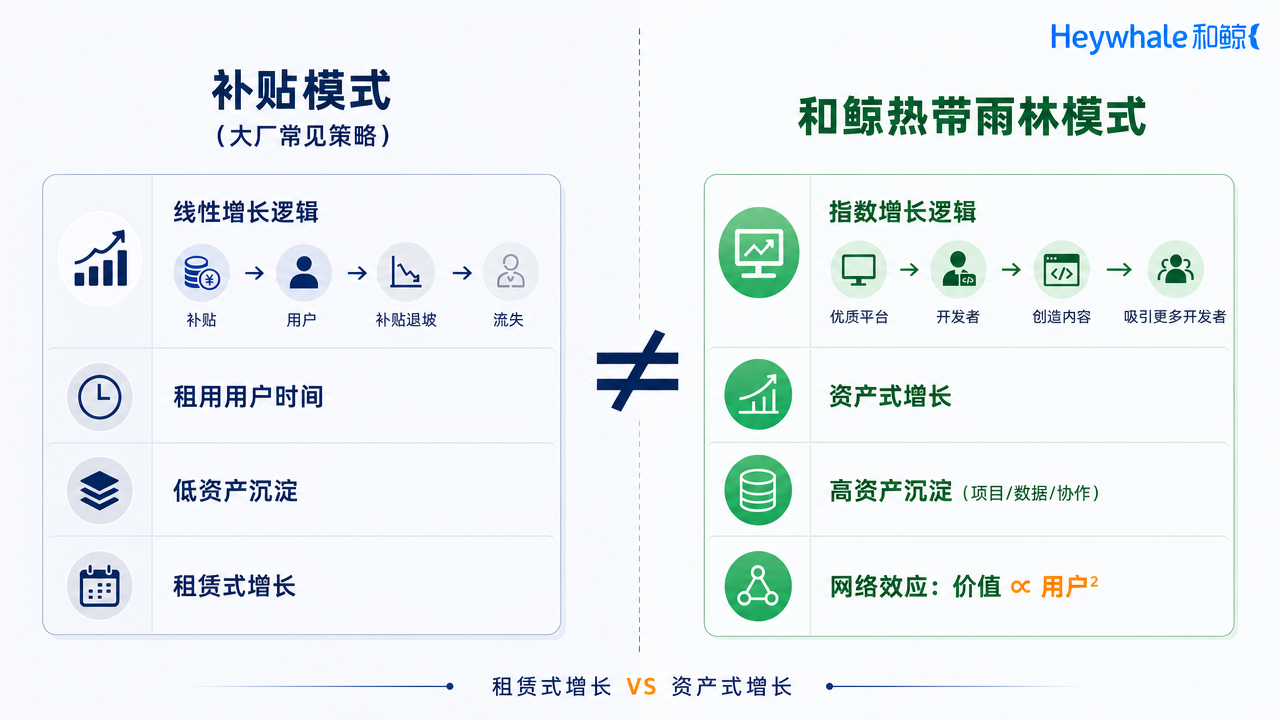
和鲸的“热带雨林”优势在于:它不仅是一个“开发者聚集地”,更是一个“价值创造引擎”。
埋下伏笔
和鲸的生态模式将如何影响商业模式延伸
生态扩张的价值,最终将体现在商业模式的多维度延伸上。随着开发者生态规模持续扩大,和鲸的Token经济有望在以下三个维度持续释放价值:
C端付费生态:当足够多的开发者把和鲸当作日常开发工具时,算力购买、模型调用等C端付费将成为规模化收入来源。这是“规模化订阅”的逻辑——非头部开发者每年贡献一两千元,叠加百万级用户基数,就是数十亿级别的年度收入。
B端企业服务:生态中的优秀开发者和优质模型,可以通过平台向企业客户输出价值。这是“价值输出”的逻辑——企业需要AI能力,和鲸生态中有现成的人才和资产,平台作为撮合方收取服务费用。
生态分成体系:当平台上的模型、应用、数据资产形成交易市场后,Token将在更多环节流转,平台从中获得持续分成。这是“生态红利”的逻辑——平台不直接创造价值,但让创造价值的人获得更高效率,从中获得合理分成。
回到开头的问题:为什么大厂都在争夺开发者?
因为开发者的力量,是AI应用生态中最难以复制和替代的战略资源。大厂可以用资本快速搭起算力底座,用补贴短期吸引开发者涌入,但开发者与平台之间的信任、协作习惯、数据资产沉淀,需要年复一年的积累。
和鲸用近十年时间,培育了一个拥有100万注册用户、10万+优质内容、5万+可复现开源项目的开发者生态。这不仅仅是数字的增长,而是一个“热带雨林”式的生态系统的自然演替——每一行代码、每一篇教程、每一个问答,都是社区用户共同浇灌的成果。
这个生态壁垒,一旦建成,就成为最深的护城河。
Token经济的浪潮之下,有的平台在“补贴”,有的平台在“种树”。和鲸选择了后者——而时间的复利,终将给出答案。

