 渠道合作
渠道合作当大模型走出"玩具箱":ModelWhale如何成为AI应用的"生产力操作系统"
2026年的中国AI市场,竞争的焦点已从"模型性能"转向"落地效能"。
和鲸ModelWhale通过重构Token经济的底层逻辑,正在将大模型从实验室的"演示玩具"转化为企业级的"生产力引擎"。
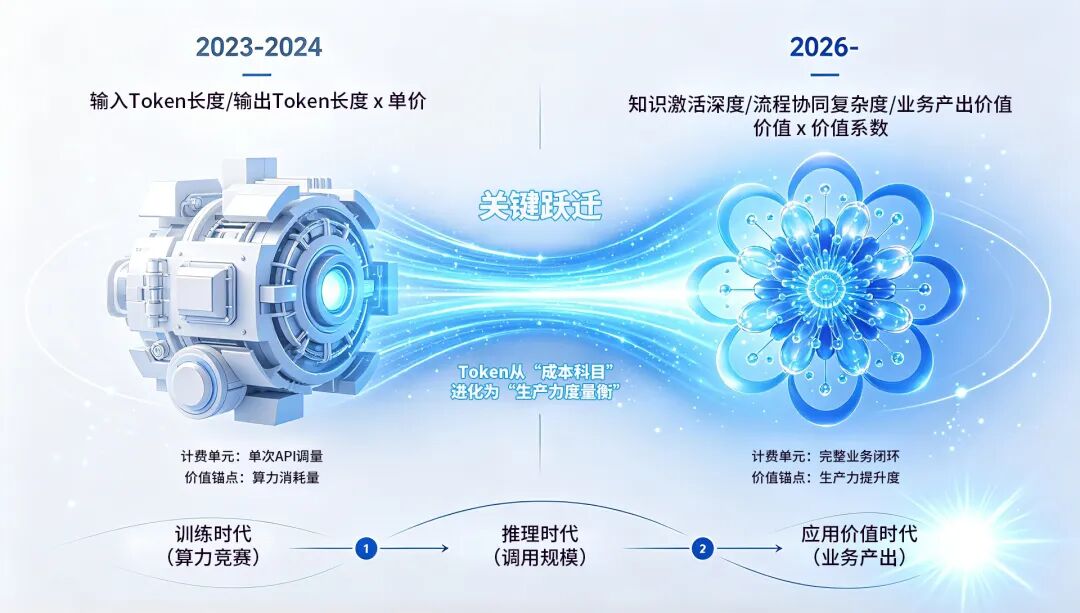
范式转移: 从"训练竞赛"到"推理时代"
行业里流传着一条时间轴:2023年是模型年,2024年是应用年,2025年是智能体元年。
那么2026年是什么?
答案是:推理年。
预计到2026年,推理带来的算力增量占比将达到三分之二,未来更将突破80%。这一判断并非孤例:汽车行业正迈入"全量推理时代",氛围编程(Vibe Coding)成为开发标配,智能座舱的个性化交互由AI实时生成。推理,正在被推到每一个终端用户面前。
Token的消耗量是最直接的证据。
据OpenRouter最新数据,仅2026年4月初一周内,全球AI大模型总调用量达到27万亿Token,环比增长18.9%。其中,中国AI大模型周调用量达12.96万亿Token,连续五周超越美国。国产模型厂商的Token与ARR均实现跃进式增长:智谱API的ARR已突破2.5亿美元,三度涨价仍供不应求,2026年Q1 Token调用量增长400%。
这组数据揭示了一个不可忽略的事实:
AI已经完成从"实验室演示"到"生产环境部署"的跨越。
当大模型走出"玩具箱"进入真实业务场景,"能不能用"早已不是问题——"能不能用好"才是。而"用好"大模型的能力,恰恰是决定下一阶段竞争格局的核心变量。
Token逻辑的重构:从"算力计价"到"应用产生价值"
过去两年,Token在行业讨论中几乎与"算力成本"画上了等号。
用户向大模型提问,消耗一定量Token,支付相应费用——这是以豆包、DeepSeek、ChatGPT为代表的通用大模型厂商建立起来的计费范式。
但这种范式存在一个根本性的盲区:
它只回答了"怎么收费",没有回答"怎么创造价值"。
当Token消耗的主体从通用对话转向行业应用时,单纯计量输入输出长度的计费方式开始显露出系统性局限。一家车企部署数千个业务智能体,其Token消耗早已不是简单的用户对话量,而是多轮推理、长上下文记忆、不同模型协同所带来的复杂算力消耗。一个科研团队搭建RAG系统处理私有知识库,其价值锚点不在每次"提问+回答"的单次互动,而在于系统能否精准理解专业术语、在封闭知识域内给出可靠答案。
这就是Token逻辑必须重构的核心变革点:
Token的真正价值不再是"你消耗了多少算力",而是"你通过消耗算力创造了多少业务价值"。
这一逻辑的转换,同样反映在算力产业链的最新动态中。2026年一季度,算力租赁行业迎来加单和涨价的"量变",商业模式也在同步升级——Token分成正在从"量变"走向"质变"。算力产业链已实质性进入全链通胀阶段,阿里、百度等大厂的云端算力资源及配套服务亦开启多轮提价。
涨价从侧面印证了需求的真实爆发,也说明了一个关键结论:
那些能够将算力消耗转化为业务产出的平台,将在新一轮竞争中占据价值高地。
这正是和鲸ModelWhale的差异化切入点。
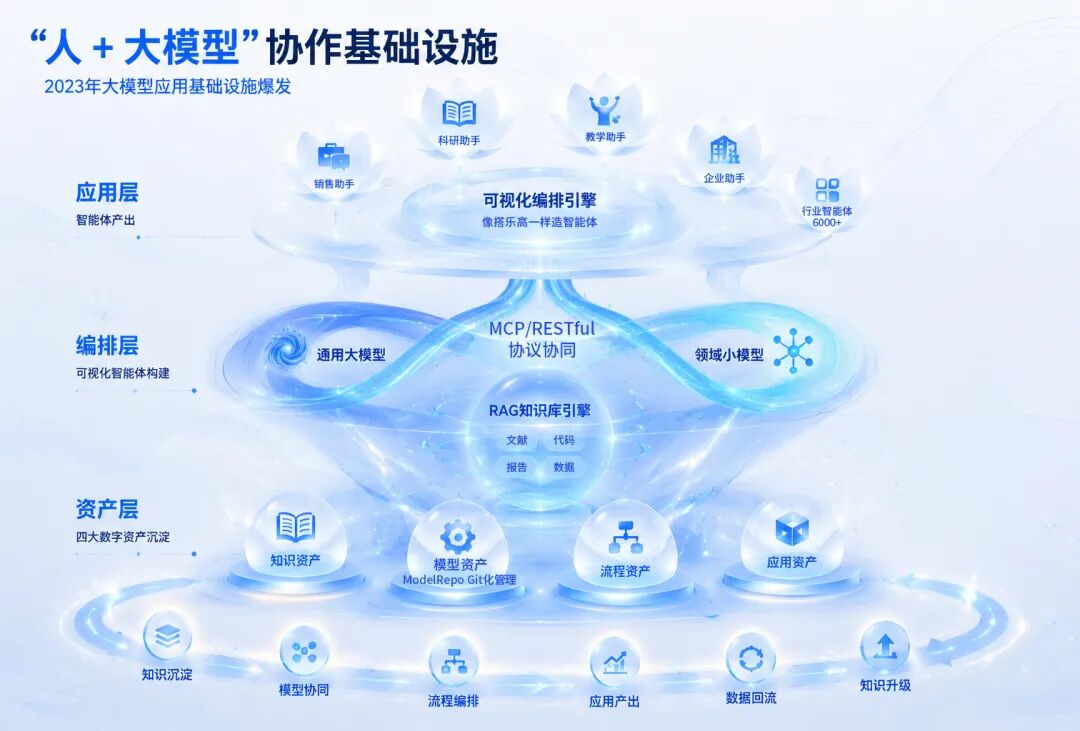
ModelWhale的"生产力操作系统":让大模型真正为业务所用
2025年,ModelWhale全面升级为大模型应用平台。
围绕"知识、模型、流程、应用"四大数字资产,平台完成了从专业工具到"生产力操作系统"的战略跃迁。这一跃迁建立在三大核心能力支柱之上。
RAG知识库:让专业团队"吃透"私有数据
在专业领域,大量高价值知识沉淀在团队内部的文献、代码、实验记录与行业报告中。
这些资产构成了行业Know-how的核心,但通用大模型在预训练阶段几乎不可能接触到它们。由此产生的"知识断层",是阻碍大模型在专业领域深度落地的首要瓶颈。
ModelWhale的RAG知识库方案直接瞄准了这一空白地带。
平台支持将团队现有的文献报告、课件等统一导入管理,并针对RAG工作流设计了完善的全流程功能支持:知识片段的导入、增删改查管理,乃至新文件的自动分段清洗,均已实现自动化。这套架构让大模型真正"吃透"了特定领域的专业知识——科研机构将学术文献与实验数据接入后,大模型的输出不再停留于通用知识的表层,而是能精准理解并调用专业领域内的研究成果。
Token经济逻辑在此发生了本质变化:
每一次RAG检索都不是简单的"算力消耗",而是一次"专业知识激活"。Token的价值不再仅停留在算力层面,而是与团队长期沉淀的知识资产深度绑定。
大小模型协同:在通用性与专业性之间不做取舍
在许多业务场景中,通用大模型覆盖面广,但回答深度和专业性往往不足;特定领域小模型准确率高,但开发部署门槛高、维护困难。
和鲸的选择不是非此即彼的取舍,而是让两者在统一平台上协同工作。
ModelWhale上线了模型Repo,采用Git化管理方案,内置常用大模型。大小模型均可通过建立远端链接,实现代码与模型在本地、平台及团队间的传输共享。在服务层面,大模型可发布为OpenAI兼容API,小模型保留RESTful API形式,并新增部署为MCP Server的能力。智能体应用层面,基于编排工具设置专用组件,可实现对RESTful和MCP服务的便捷调用。
这套体系在产业端已展现出实际价值:
某车企部署大模型平台后,半年内开发超过6000个智能体,覆盖集团10万以上用户,沉淀出100多个精品应用。这些智能体不是孤立的工具,而是具备感知、决策与执行闭环能力的"AI员工"。
Token消耗由此从用户对话扩展到了企业内部流程的每一个环节。ModelWhale将这种复杂的协同调度封装为即开即用的平台能力,让企业无需从零搭建即可获得"大小模型协同"的能力。
可视化智能体编排:像搭乐高一样造智能体
如果说前两项能力解决的是技术供给侧的短板,可视化编排则解决了最后一个"最后一公里"难题:
谁来搭智能体?
真正的门槛不在模型本身,而在于如何将多个模型、多种能力、多个知识库串联成一个可执行的工作流。大多数企业连基本的端到端流程都梳理不清,却同时被要求输出高价值的AI解决方案——这本身就存在结构性矛盾。
ModelWhale的编排工具提供了可视化、低门槛的解决路径:
通过拖拽配置即可组建AI工作流,一键连通平台所有知识和模型资产。这套工具支持对接外部LLM与MCP服务,满足多领域用户根据实际工作场景设计和快速搭建智能应用的需求。
工程复杂度从企业内部剥离,从概念验证到生产部署的周期被极大缩短。
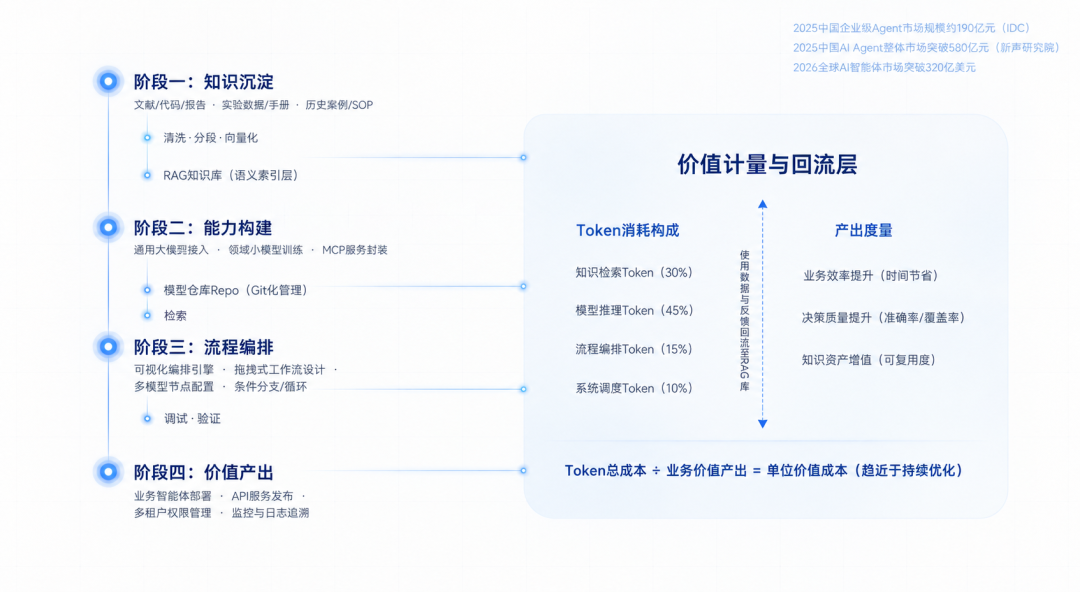
Token的下一站:当"应用开发"成为可计价的商品
讲到这里,这套"生产力操作系统"的Token逻辑已经变得非常清晰。
过去的Token经济是一个单向的计量模型:
用户提交输入 → 模型生成输出 → 按长度收费
但在ModelWhale的体系中,Token正在经历一场意义深远的重构。
当开发者通过拖拽配置构建一个多智能体协作应用时,背后的代码管理、知识库检索、模型协同等环节所产生的Token消耗,不仅仅是计算资源的体现——应用开发本身的"工程量"被量化为可交易的商品。
这套逻辑的直接商业价值体现在:
Token消费场景从单一的"模型调用",扩展到了"应用开发—知识沉淀—模型托管—智能体部署"的全链条。每多一个环节被Token化,平台上的价值流转就增加一个维度。
这并非凭空创造需求,而是沿着行业刚需顺势而为。
根据IDC数据,2025年中国企业级Agent市场规模约190亿元人民币,预计2025-2028年复合增长率超110%。新声研究院报告显示,2025年中国AI Agent整体市场规模已突破580亿元。全球AI智能体市场规模将在2026年突破320亿美元,其中具备全链路能力的平台占比将超过65%。
被低估的价值洼地:从模型突破迈向规模落地
将以上视角集合并串联,我们可以从更宏观的维度理解ModelWhale所处的市场位置。
和鲸ModelWhale正在做的,不是大模型赛道的"备选方案",而是AI产业从模型突破迈向规模落地的关键桥梁。
Token经济表面上是计量工具,深层逻辑则是在重新定义AI产业的价值分配方式。当一家企业部署上百个业务智能体时,为其创造最大价值的不再是谁提供了"最强的基座模型",而是谁能提供一个让智能体"顺利跑起来、安心管起来、持续迭代起来"的中枢平台。
在这个新赛道上,和鲸ModelWhale凭借早期布局和产品深度,已经建立了无法忽视的时间壁垒与市场定力。
更深层的机会在于:
当行业从"模型能力崇拜"转向"应用效能竞争",平台型企业的价值捕获能力将呈非线性增长。ModelWhale的"生产力操作系统"本质上是在构建一个"AI应用的基础设施层"——这一层的位置,决定了它能够在整个智能体经济中持续抽取价值,而不受单一模型厂商兴衰的影响。

