 渠道合作
渠道合作同济大学特聘研究员胡维老师实录分享:在“大模型×经管科研”背景下关于高效科研的思考
导读
大语言模型(large language model,LLM,以下称“大模型”)的快速发展正在重塑科研范式,但其能力边界与伦理挑战亟待厘清。在4月12日由和鲸社区联合上海人工智能实验室OpenDataLab平台主办的“大模型赋能科研分享会”上,同济大学经济与管理学院特聘研究员胡维老师以《大模型×经管科研:关于高效科研的思考》为题,结合会计、金融、营销、运营管理等领域的实证研究,剖析大模型在经管研究中的潜力与应用。
分享会上胡老师讨论了关于大模型在经管领域的科研应用方向、案例及相关思考,强调了科研工作者需在“工具赋能”与“伦理约束”间寻求平衡,探索人机协作的最优路径,旨在为参会人员提供将大模型作为经管领域科研工具和创新灵感的方法指南。
分享嘉宾
胡维 同济大学经济与管理学院特聘研究员

以下为实录分享内容
Part 1 大模型现状
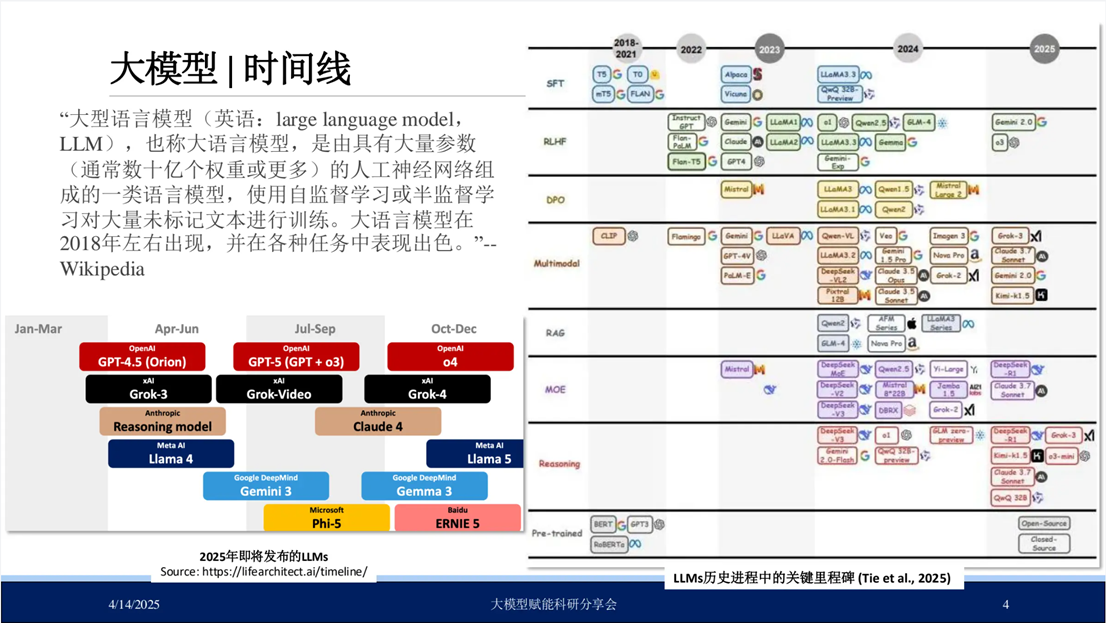
大语言模型(Large Language Models, LLMs)相较于传统基础语言模型,其参数规模显著扩展。如下图右侧图表所示,近年来大模型发展进程呈现加速态势,代表性成果包括:OpenAI研发的ChatGPT 3.5与4.0版本,以及国内开源的DeepSeek-R1模型,左下图表进一步呈现了媒体对2025年大模型发展趋势的预测,表明未来将有更多创新模型持续涌现。
当前,学界与产业界对大模型的技术优势已有充分共识。然而,需明确界定其能力边界及合理应用路径。OpenAI首席执行官Sam Altman曾预测,未来十年内人工智能将实现第五级能力(Level Five),其定义为具备组织管理职能的系统级人工智能(Organizational-Level AI)。
而现阶段主流大模型技术处于第二级能力阶段(Level Two)。第一级主要表现为基础对话交互功能,典型代表为传统聊天机器人;第二级则实现初步逻辑推理能力,以DeepSeek-R1等先进模型为例;第三级涉及具备任务执行能力的智能代理系统(AI Agent);第四级将实现创造性内容生成与自主开发功能;最高级别的第五级则规划为具备组织管理与战略决策能力的智能系统。
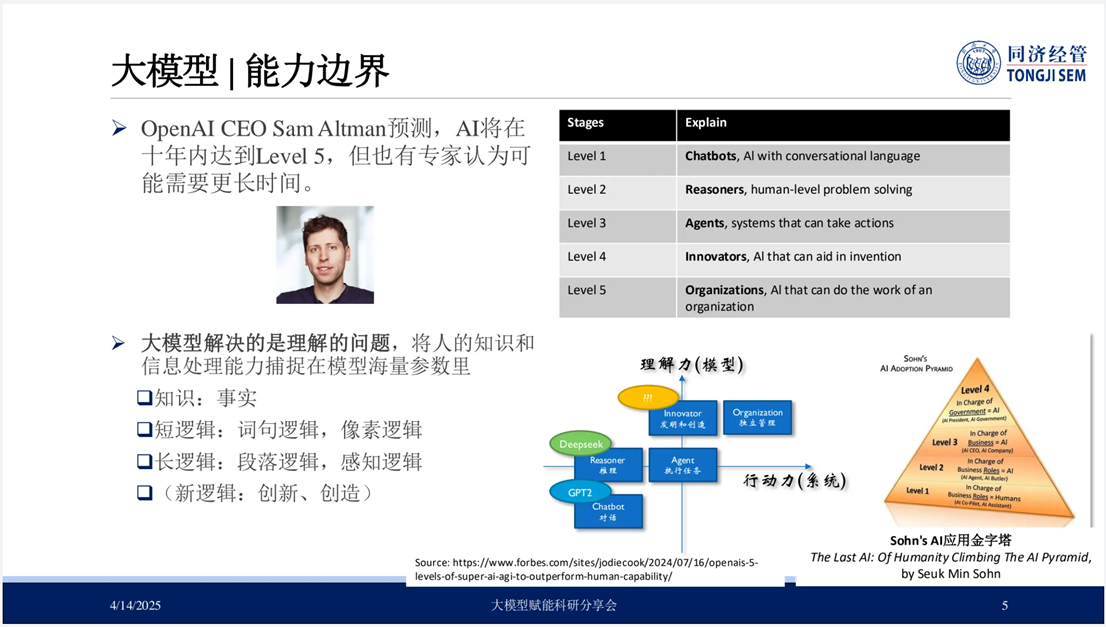

因此,在大模型的应用实践中,我们需明确当前大模型的能力边界,主要涉及以下三个关键问题:
该现象具体表现为大模型产生连贯且语法正确的输出,但却与事实不符或毫无意义。其成因主要包括:训练数据中包含事实性错误内容;产生“符合”句子结构但不准确的虚假信息;生成过程缺乏充分事实基础。目前,针对“幻觉”问题已衍生出诸多解决方案。
近两年来发表于《Nature》中的三篇研究成果的核心议题均围绕大模型“幻觉”问题展开。其中前两篇研究呼吁技术研发团队、学术界及社会各界充分认知该问题的重要性,并致力于提升模型的可靠性。最后一篇论文则提出一种基于语义熵(semantic entropy)的方法,为在一定程度上解决“幻觉”问题提供了新的解决思路。
由LLM生成的文本和图像中均存在刻板印象问题。
- 在文本生成领域,有学者针对大模型生成文本展开研究,发现自ChatGPT发布以来,“人工智能流行词”在科学论文中的出现频率呈显著上升。
- 在图像生成领域,有研究通过设计多样化的提示词(prompt)进行图像生成实验,发现图像大模型对特定群体的视觉呈现存在显著刻板印象。例如,“印度人”几乎总是一个留着胡子的老人;“墨西哥人”通常是戴着宽边帽的男人等。
因此,在使用大模型开展严谨的学术研究或专业工作时,需充分关注并规避此类潜在风险。
这是当前学术界,尤其是社会科学领域科研工作者关注的重要议题——人类在使用大模型或广义 AI 技术后可能出现的去人性化倾向。有研究发现,人类与 AI 的交互会显著提升不道德消费行为的发生倾向,其余两项研究也呈现出类似结论。
其逻辑机制相对明确:由于 AI 被认知为“非人类主体”,高频次交互可能导致个体在社会行为中对人性特质的感知与践行出现弱化。这一现象在学术研究中具有独特价值,有相关研究针对该问题提出了具体干预路径。

基于上述内容,大家在使用大模型时需要谨慎,其中提示工程(Prompt Engineering)在对话交互场景(如聊天机器人开发)中具有核心价值。建议关注前沿的提示工程指南(Problem Engineering Guidelines),系统学习链式思考等精细化提示技巧。
如果大家想掌握大模型领域的前沿动态,可通过专业平台如Artificial Analysis LLM Performance Leaderboard、Hugging Face大模型基准集进行探索和学习。
Part 2 大模型助力经管科研:案例
第二部分我们聊聊经管领域近两年来的大模型相关科研案例。从技术研究路径出发,可归纳为以下三个方向:将大模型作为研究情境(context);将大模型作为研究对象(object),该方向主要由计算机科学与工程学科主导;将大模型作为研究工具(tool)。
《Review of Financial Studies》中一项研究将BERT预训练模型应用于研究设计,尽管 BERT 严格意义上不属于大模型范畴,但研究团队借助构建了一种用于研究公众的“金融情感”如何随时间和国家变化。
研究案例2 将GPT-4等生成式大型语言模型应用于会计专业文本分析,其在复杂任务中表现优于传统方法,准确率达96%,错误率显著降低。
作为经管学科中技术接纳度最高、开放性较强的分支,该领域近两年围绕大模型的研究成果颇丰。


案例研究了制造业服务化对牛鞭效应的影响,发现服务化通过信息共享减少需求波动,并通过提升生产效率降低企业内部牛鞭效应,还验证了大模型(如GPT-4)在文本挖掘中的应用一致性。此外,类似案例基于相似方法,通过大模型从评论中提取与伦理相关的指标来辅助得到研究结果。
Part 3 总结
- 研究者应注意清晰界定大模型的能力边界,探索符合自己的协作最优模式;
- 研究者需要坚守技术应用的伦理与规范底线,包括学术诚信准则、数据隐私保护和透明性要求。
- 研究者要关注技术发展的趋势和机遇,运用大模型提升科研效率的同时,也需警惕思维同质化风险,注重独立思考和深度拓展。

