 渠道合作
渠道合作探析同济医院科研一体化平台建设(一):降低科研门槛,实现科研提速
医疗产业正经历由信息化到智慧化的转型过程,期间,国家多次发文强调临床研究与诊疗协同的重要性,高水平研究型医院成为临床研究的主阵地。与此同时,AI for Science 科学研究范式的涌现标志着生物医学研究迈入新阶段,大数据与 AI 技术成为科研探索的有力支撑。
在此背景下,华中科技大学同济医学院附属同济医院作为高水平研究型医院,在数智化建设应用方面开启新征程,携手和鲸科技打造医院科研管理服务一体化平台。
 图源:华中科技大学附属同济医院官网
图源:华中科技大学附属同济医院官网
针对研究型医院普遍面临的数据孤岛、重复造轮、产研分离等问题,该平台提供从数据提取、模型产出到科研转化的全链路服务,融合研究所需的多规格算力,为跨团队跨角色协同管理提供工具支持,可达成“降低科研门槛,减轻科研负担,加速科研进程”的核心目标。
将跟随和鲸视角,我们将通过三大关键场景探析平台的建设理念与应用实效,为我国研究型医院的建设提供有价值的参考与借鉴。这三个场景分别为:
降低科研门槛,实现科研提速
统筹科研项目,促进成果转化
科研人才分层培养
注释:篇幅原因,我们将三个场景拆分为了三篇文章,本文为此系列的第一篇。全系列请查看资讯中心。
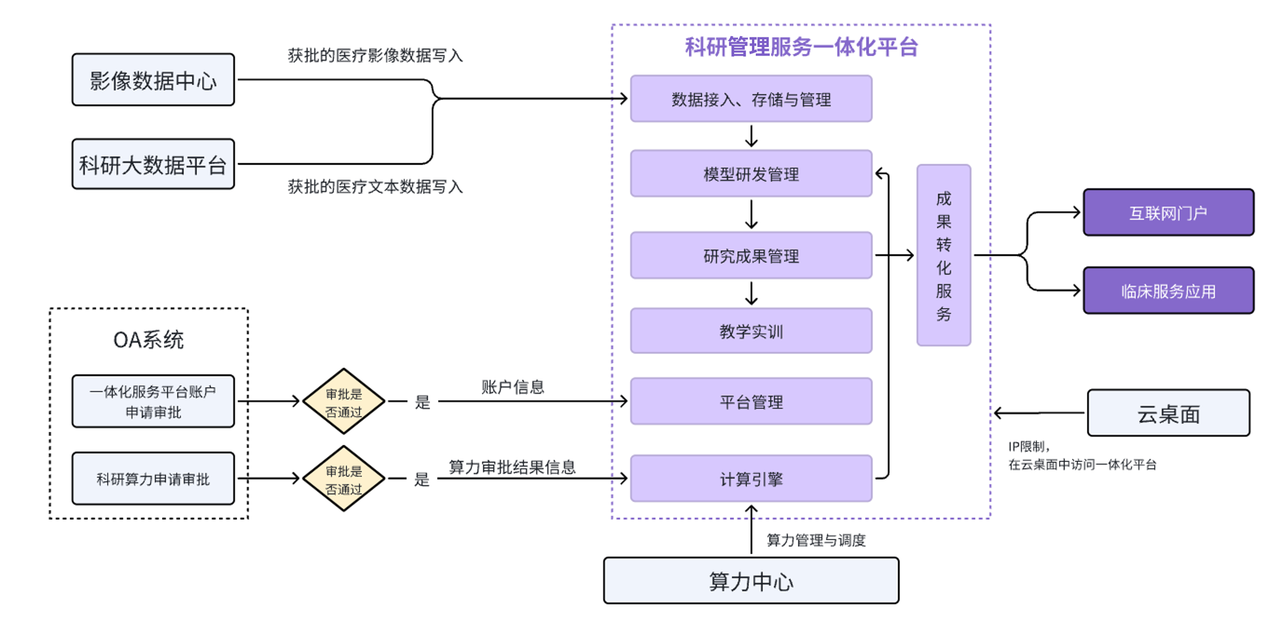
平台与院内科研相关系统整体关系架构展示
降低科研门槛,实现科研提速
AI4S 从科学家为主导的概念导入期,进入到以科学家和工程师协作为标志的大规模基础设施建设期。
为了使临床科研能更快地完成算法驱动下,数据、算法、算力“三位一体”的计算方式变革,帮助科研人员(含临床医生、研究者及学生)更高效地投身于研究工作,同济医院立足科研工作切实需求,分两步推进:
1. 实现多渠道服务的衔接,优化研究资源分配机制:
优化数据服务,化解数据资源分散困境与数据泄漏风险,提升研究人员获取数据的便捷性;
优化算力服务,达成算力使用关联至课题,通过统一纳管、弹性调度提升资源利用率。
2. 引入低代码建模工具,模板化科研流程:通过环境配置、分析建模范式以及算法仓库化三种途径降低研究门槛,使重复性工作便捷化、半自动化。
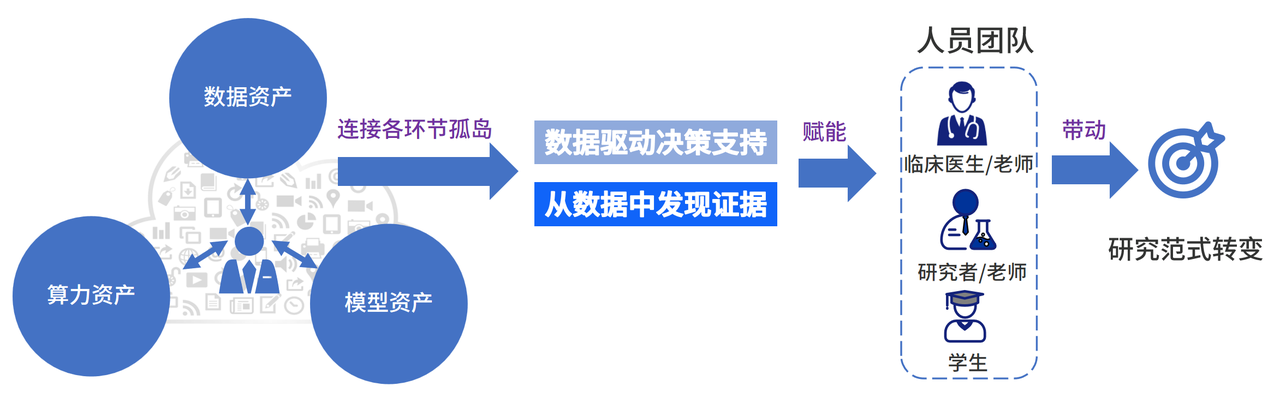
一体化服务平台的目标
举措一:实现多渠道服务的衔接,优化研究资源分配机制
在 AI4S 的研究范式下,模型受到数据与算力的高度制约与影响,因此平台首要解决的便是数据服务与算力服务的问题。
数据:便捷获取,安全管控不出云桌面
目前,院内已积累了海量医疗数据与各专病库数据,包含原始文本数据、影像数据、检验数据、研究产出结果数据等。
在过去的流程中,研究人员针对特定科研项目发起文本或影像数据申请、通过 OA 审批流程后,可以从院内数据湖中抽取相应数据。其中,获批的影像数据需要研究人员携带电脑或存储介质自行往返下载使用,这样会产生较高的人力成本,且数据脱离了医院监管视野后无法知晓其后续传播情况,给数据安全埋下了隐患。
科研管理服务一体化平台对数据服务做了整体升级。下图展示了数据服务的前后对比,能够清晰地看到方案升级后的流程变化。
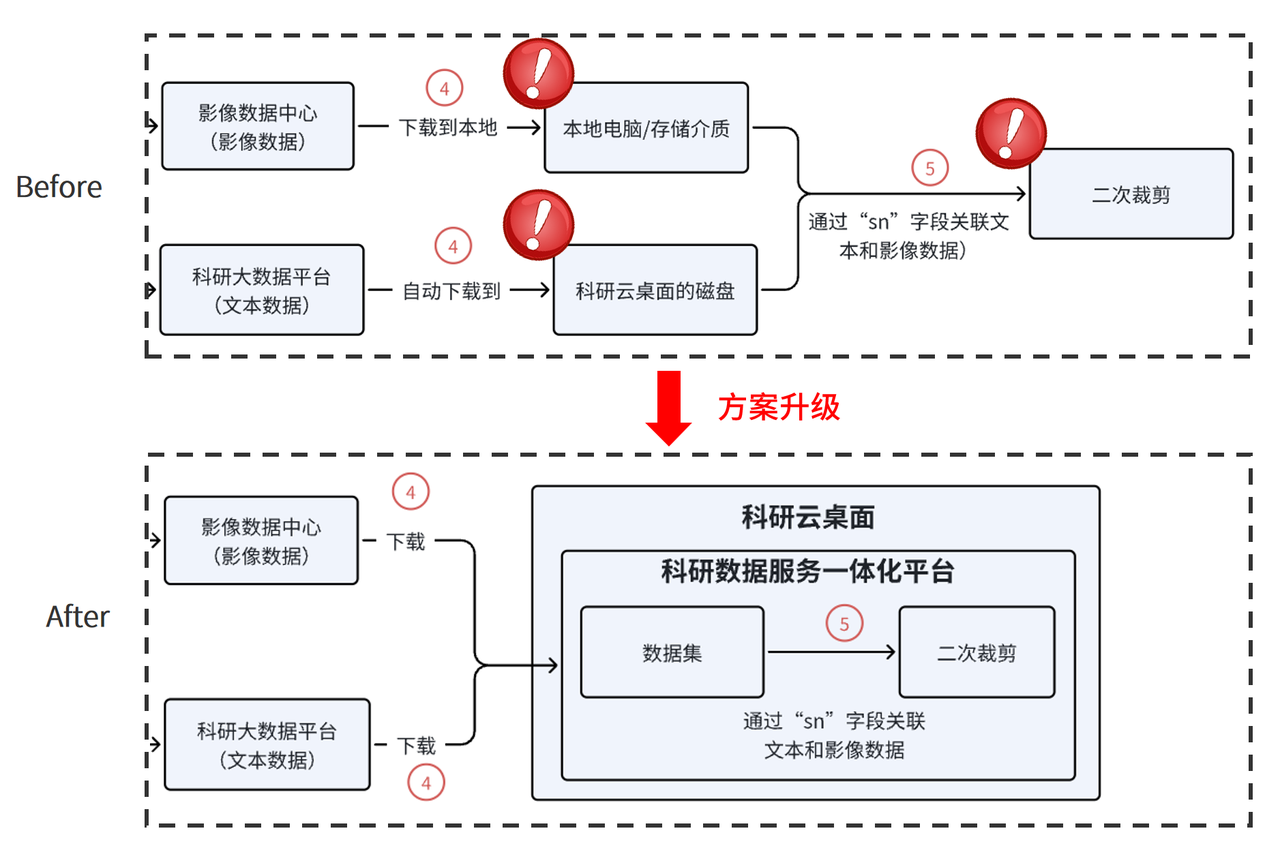
数据服务的前后对比
1. 数据获取:获批的影像数据将直接存储到平台接入的个人可用的 NAS 文件夹中。平台对于微观组学数据、临床文本信息、多模态影像数据等多来源、多类型、高复杂的医学数据,都能高效地接入、存储与管理。
2. 数据使用:接入数据后,研究人员可以直接挂载数据开展分析建模工作,但原始的医疗数据通常无法直接使用,需要对数据进行“二次裁剪”(指对数据进行预处理),在达到分析要求后再使用,此部分内容将在“举措二”中作更完整的说明。
3. 数据安全:数据的安全防护设置了双层保障机制。第一层依靠平台的权限管理系统,在数据分发时可设定为仅使用或可下载;第二层借助 IP 限制手段,将平台访问锁定在科研云桌面内,确保数据流通不出云桌面。
4. 数据复用:对于临床常用的公共数据集,平台还提供了共享空间,便于科研人员灵活取用。
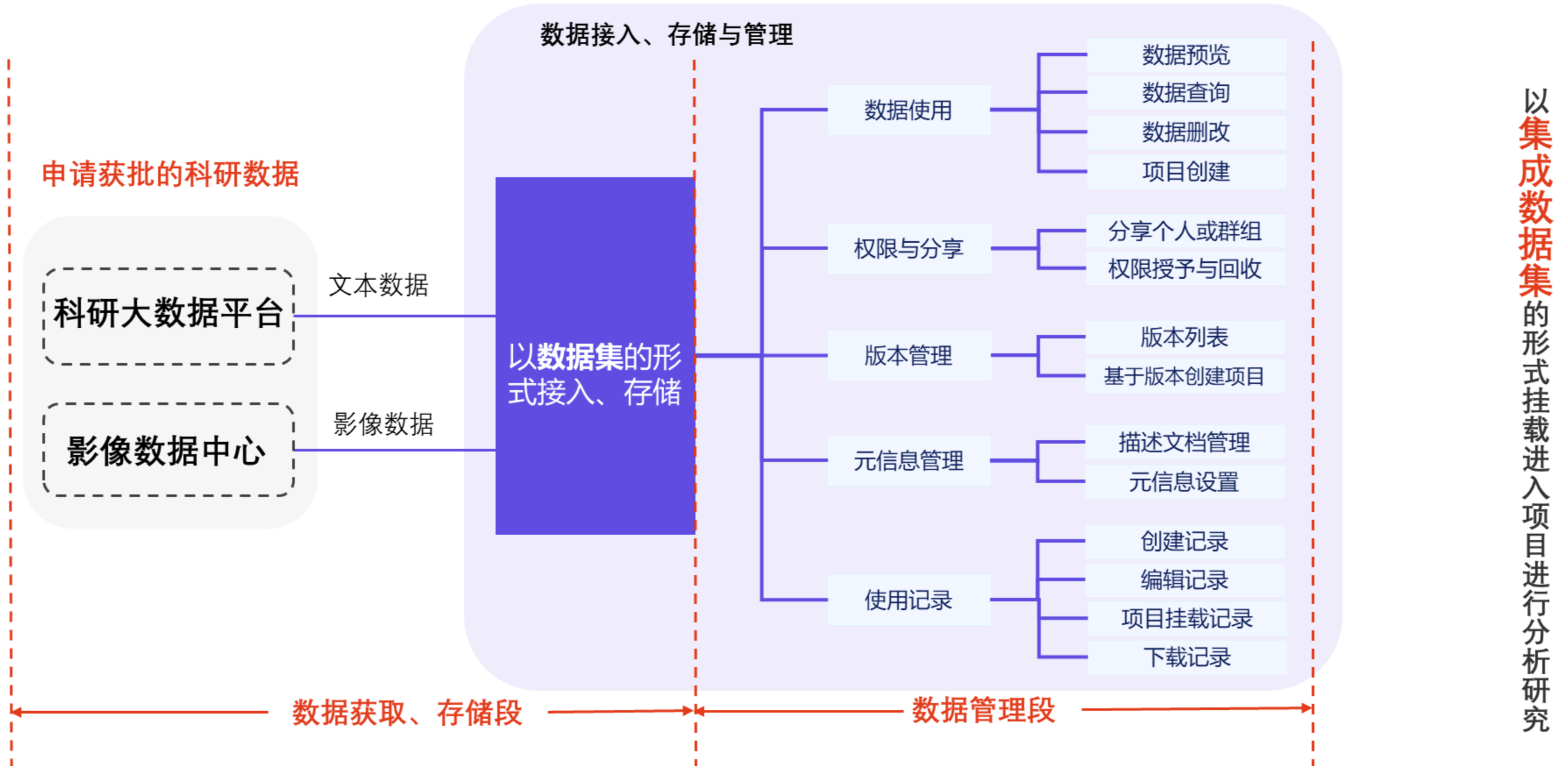
平台数据服务全景展示
在平台的冷启动阶段,检验科的医生们率先感受到了数据服务优化带来的便捷性。“原来总是要带着硬盘来来回回地去拷贝数据,现在直接自动发放到个人空间,方便太多了。”
正式上线后,平台预期接入更多元的数据源,包括公共医学数据集、多中心公共卫生数据集,以及基础科研实验记录等,进一步拓展数据服务的广度与深度。
算力:统一纳管,关联课题,弹性调度
算力服务升级遵循 “以用为本” 的原则:对于研究人员来说,要能用、够用、好用;对于医院来说,要用上、用好、用对。
下图展示了算力服务升级前后的对比。平台建成后,算力资源由原先的各科室独立采购转为由平台统一纳管。平台与医院 OA 系统已实现无缝对接,而串联研究人员与医院双方 “三用” 需求的关键纽带则是别具匠心的 “算力代币机制”。
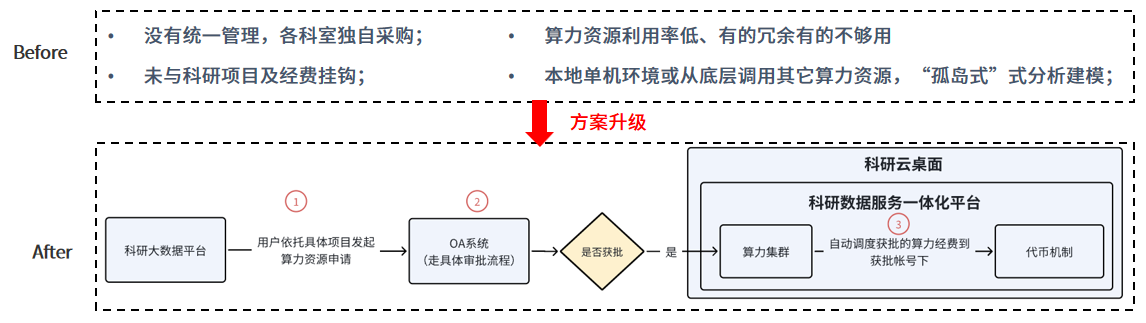
算力服务的前后对比
从研究人员角度出发:
依据具体研究项目提交算力资源申请,经 OA 系统审批通过后,管理员会将对应算力代币下发至平台项目课题组负责人账号。负责人可以按照课题组的分工将代币灵活地共用、转让或二次分配;
算力代币可以用于购买平台内丰富多样的算力资源,涵盖 GPU 集群、高性能 GPU 以及多规格 CPU 等,充分满足不同科研任务对算力的差异化需求,实现按需取用,灵活高效。
而从医院视角来看:
借助平台云原生的架构优势,实施算力需求的动态调配与精细化管理,可以巧妙化解资源调度难题。由于此分配仅涉及额度调配,使用者并不实际独占资源,可以让医院的算力资源真正地“忙起来”,创造更多价值;
更重要的是,平台与 OA 系统的打通形成了与课题经费紧密挂钩的算力审批-充值管理体系。该体系下,管理员只需通过点选式的分配操作即可实现统一有序管理,简化了运维流程,减轻人力负担。
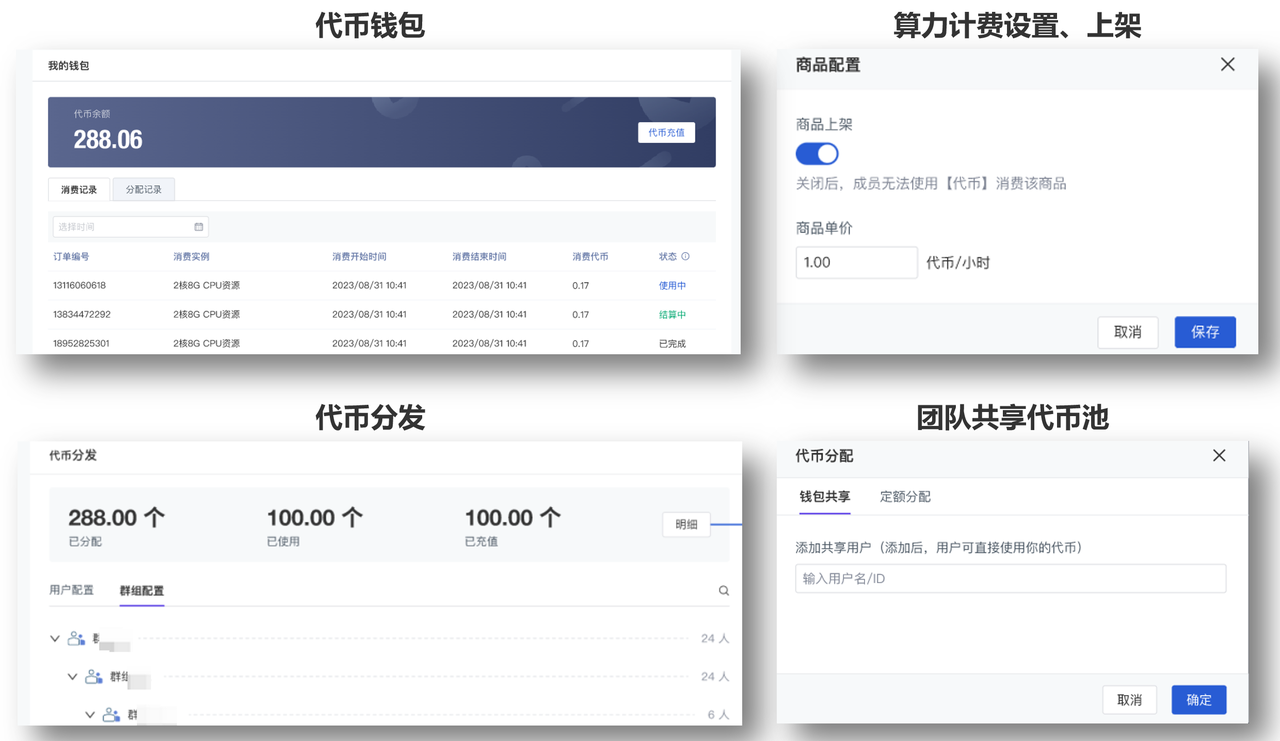
算力代币充值管理机制
举措二:引入低代码建模工具,模板化科研流程
当前临床研究数据的复杂程度日益攀升,以往 SPSS 等软件尚能应对数据处理工作,但技术的发展使得代码算法编写逐渐成为主流趋势。而临床医生这个群体,大部分都没有代码和工程基础。
同济医院洞察这一矛盾,在着力提升基础设施(研究资源)获取便捷性的同时,充分考量不同工程能力研究者的需求特性,从环境配置、分析建模范式以及算法仓库化这三个方面出发,打造适配性强的工具支持体系。
环境配置
降低研究门槛的第一步就是将临床医生从繁琐的环境搭建中解放出来。
平台提供了即开即用的分析环境,将丰富的 Python、R 语言工具包和深度学习框架都进行内置,包括常用的医学领域的数据包也都已预装好,这一整套下来,基本可以满足多数临床医生的简单模型实验。对于工程能力更强的研究者,也可以根据研究需要自定义分析环境。
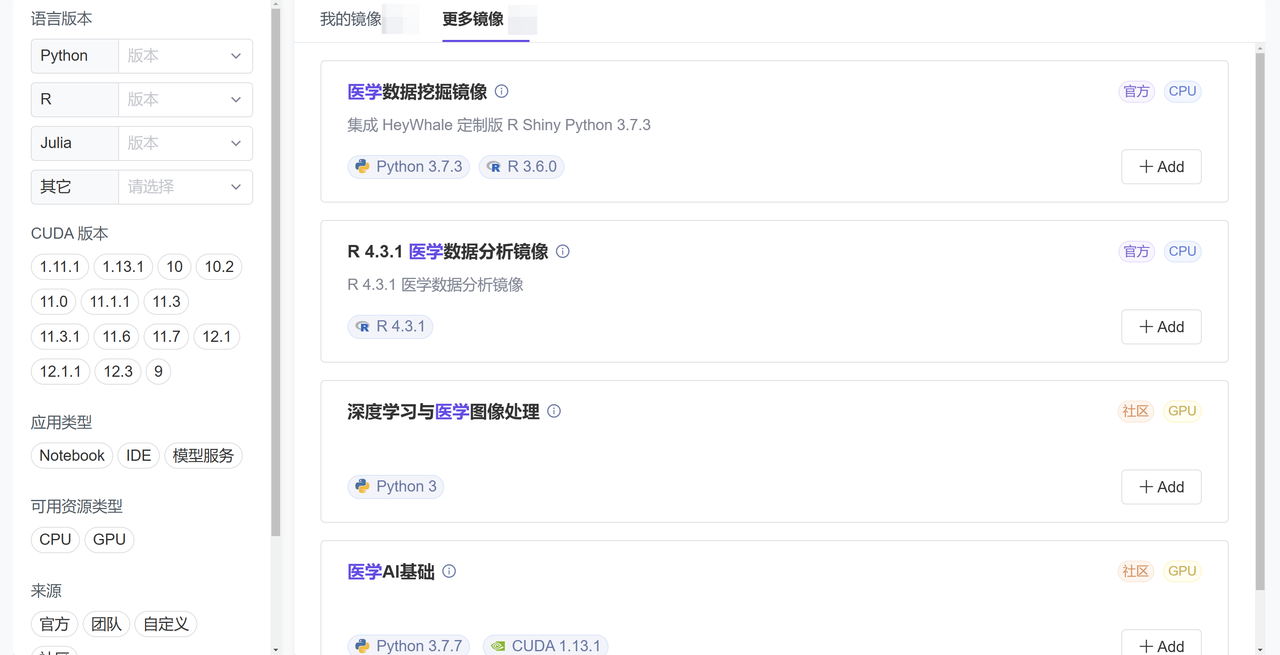
平台内置的部分医学分析镜像环境展示
分析建模流程
平台同时提供了 Jupyter Notebook 交互式分析建模和 Canvas 低代码拖拽式建模。Jupyter Notebook 比较常见,这里着重介绍一下后者。
低代码的组件是临床医生与工程师共通的视觉语言。在开展分析时,有编程或统计学基础的临床医生可以通过拖拉拽组件自行搭建分析流程和框架,先捋研究思路再考虑算法实现的工作流会更贴合临床医生的习惯,也有利于帮助临床医生向数据科学家转型;完全没有基础的临床医生想要从头自己搭建可能有点困难,但他们可以直接使用他人封装好的分析模板,只需要替换数据/修改参数,也能实现快速分析与临床验证。
技术之 “智” 赋能医疗之 “治”,人工智能等前沿技术的发展必将有力推动医学科学研究,希望同济医院与和鲸的探索能够为业界提供有益的借鉴。
欲了解更多医院建设的案例、技术细节、应用成效,您可以扫描下方二维码进一步与我们沟通!也欢迎您点击阅读原文注册试用和鲸 ModelWhale 平台(建议用pc端打开),切身体验上述案例中的各项平台能力。
Canvas低代码组件分析流展示
算法“仓库化”
同济医院也十分注重科研“过程成果”的沉淀,往往这是减少重复性工作、提升科研效率的关键。
在平台中,代码片段库、算法库、模型库等成为了 “过程成果” 的载体,研究者可以把任何形式的阶段性成果封装为模板,辅助他人开展研究(在下一篇中将有更具体的说明)。
在平台的试运行阶段,众人发现了一个微小而重要的场景。
前文曾提及,原始的医疗数据一般难以直接应用于分析,需要对其实施 “二次裁剪” 操作——比如提取患者在特定时间段内的数据,或是摘取患者最后一次的检查、诊断、预后数据,亦或是依据其他特定分析要求进行裁剪。针对部分通用的裁剪需求,多数情况下只是需要替换不同的医疗数据来获得不同的结果,因而其中便产生了大量重复性工作。
平台上线后制作出了多种数据“二次裁剪”的模板,包括涉及代码的 Notebook 模板、低代码的 Canvas 模板以及借助模型服务(指将模型部署为 api 服务或网页应用,在下一篇中将有更具体的说明)生成的网页工具。研究人员使用时只需替换数据路径,即可快速获取裁剪结果。
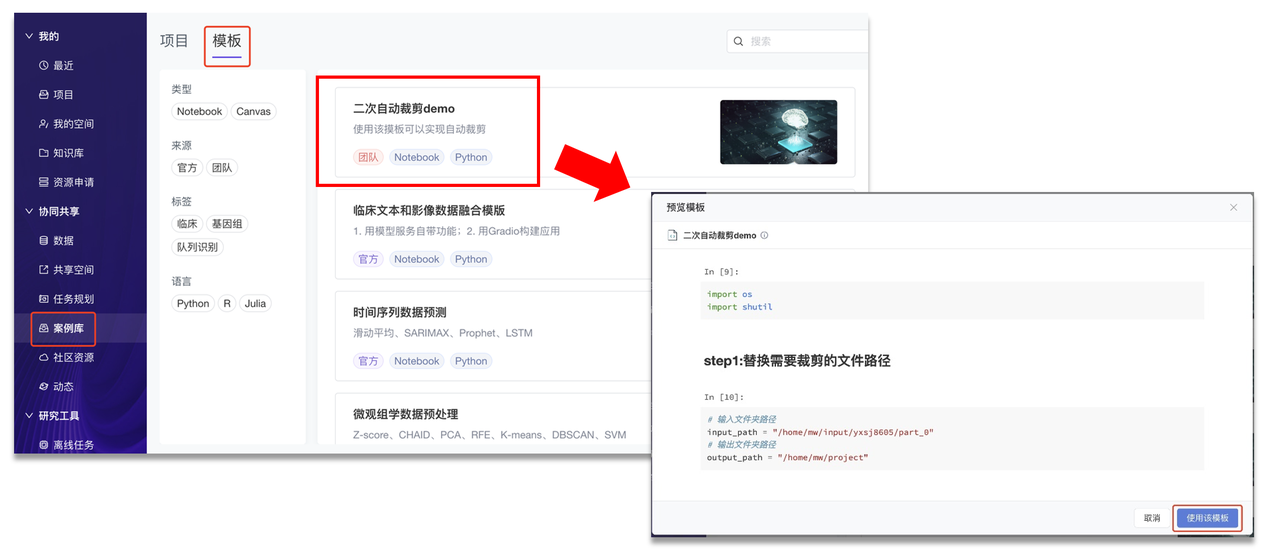
二次裁剪模板展示
技术之 “智” 赋能医疗之 “治”,人工智能等前沿技术的发展必将有力推动医学科学研究,希望同济医院与和鲸的探索能够为业界提供有益的借鉴。
欲了解更多医院建设的案例、技术细节、应用成效,您可以扫描右侧二维码进一步与我们沟通!也欢迎您注册试用和鲸 ModelWhale 平台,切身体验上述案例中的各项平台能力。

